
GGPLOT2 is a package developed for producing graphics within the R statistical tool. It utilizes a layering metaphor for gradually adding visual details to the desired output. R can support datasets with millions of rows for various aggregation and analysis operations, but it can be slow, unwieldy to code in, and has memory limitations. This article walks through the development of a complex scatter plot using NFL (American football) data. This dataset was developed in an earlier article, the gist of which can be viewed below (in an Oracle database).
The rows in this table contain individual scores for all 256 games of the regular season, excluding the playoffs. The Oracle SQL below builds some useful aggregate stats off of this base data for each of the 32 teams in the NFL: average offense (points scored), average defense (points scored against), average victory (or defeat) margins, and some ranking info for each of these elements, and a constructed new element called ‘Power Factor’ which combines the defensive and offensive rankings into an overall efficiency rating.
w h i t e s p a c e
WITH base_stats AS
(
SELECT team,
SUM(DECODE(wlt, 'WIN',1.0, 'LOSS',0, 'TIE',0.5, 0)) wins,
AVG(ptsf) AS pts_off,
AVG(ptsa) AS pts_def,
AVG(ptsf) – AVG(ptsa) AS pts_margin
FROM nfl2012_scores
GROUP BY team
),
interim_stats AS
(
SELECT team, wins, pts_off, pts_def, pts_margin,
RANK() OVER (ORDER BY pts_off DESC) AS rank_off,
RANK() OVER (ORDER BY pts_def ASC) AS rank_def,
RANK() OVER (ORDER BY pts_margin DESC) AS rank_margin,
64 – (RANK() OVER (ORDER BY pts_off DESC)
+ RANK() OVER (ORDER BY pts_def ASC)) AS power_factor
FROM base_stats
)
SELECT
team, wins, pts_off, pts_def, pts_margin,
rank_off, rank_def, rank_margin, power_factor,
RANK() OVER (ORDER BY power_factor DESC) AS power_rank
FROM interim_stats
/
w h i t e s p a c e
The results from the above query can be exported into R using SQL Developer‘s CSV output option. If preferred, one could use RODBC to open a connection between R and the database, if you don’t mind typing some complex SQL commands directly into the R environment. The example below shows the former method.
Now, let’s demonstrate using GGPLOT2 to craft a visualization of this data, in layered steps. The goal is to make the graphic result potent with meaningful information without going overboard and producing clutter.
w h i t e s p a c e
# grab the data from the Oracle CSV file into R
> nfl <- read.csv("nfl2012_stats.csv", header=TRUE, sep=",", as.is=TRUE)
# ggplot2 needs external library packages — if not previously installed
> install.packages(c("plyr", "reshape2", "stringr", "ggplot2"))
# load package into R memory for present workload — necessary each R session
> library(ggplot2)
# expose the dataframe to GGPLOT2…
> sp <- ggplot(nfl, aes(PTS_DEF, PTS_OFF, color=POWER_FACTOR))
# build scatter plot foundation…
> sp <- sp + geom_point(shape=20, size=.6*nfl$WINS) + scale_x_reverse()
+ scale_colour_gradient(low = "red")
# set up axes labels and titles…
> sp <- sp + xlab("Defensive Prowess >>") + ylab("Offensive Prowess >>")
> sp <- sp + ggtitle("NFL 2012 Regular Season")
# add break-even diagonal and print…
> sp <- sp + geom_abline(intercept = 0, slope = -1, colour = "green", size = .75)
> sp
w h i t e s p a c e
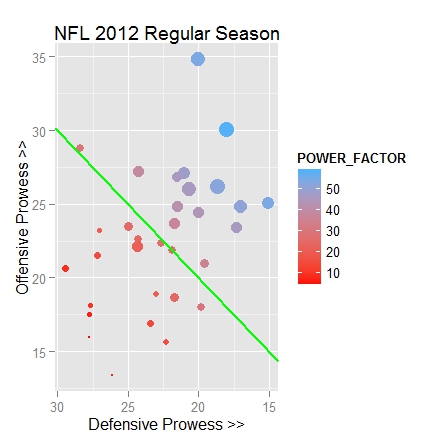
This much produces the basic scatter plot (below left), with plotted points and some labelling. The diagonal green line indicates the barrier between winning(scoring more points than opponent) and losing(scoring less points than oopponent), in aggregate.
w h i t e s p a c e
# undo default Legend for color gradient…
> sp <- sp + theme(legend.position=”none”)
# add shaded regions for top quintiles…
> sp <- sp + annotate("rect", xmin = 14, xmax = 19.75, ymin = 20, ymax = 33, alpha = .1,
colour = "brown")
> sp <- sp + annotate("rect", xmin = 17, xmax = 29, ymin = 26.6, ymax = 35.6, alpha = .2,
colour = "orange")
> sp <- sp + annotate("text", y = 35, x = 26.8, label = "OFF. TOP 20%", size=3)
> sp <- sp + annotate("text", y = 20.7, x = 16.2, label = "DEF. TOP 20%", size=3)
# add team names for each plotted point…
> sp <- sp + annotate("text", y = 34.5, x = 20.6, label = "NE", size = 2, color = "dark blue")
> sp <- sp + annotate("text", y = 29.8, x = 18.8, label = "DEN", size = 2, color = "dark blue")
> sp <- sp + annotate("text", y = 28.7, x = 27.9, label = "NO", size = 2, color = "dark blue")
. . .
> sp <- sp + annotate("text", y = 24.8, x = 22.1, label = "BAL", size = 2, color = "dark blue")
> sp <- sp + annotate("text", y = 21.8, x = 22.7, label = "CAR", size = 2, color = "dark blue")
> sp <- sp + annotate("text", y = 22.7, x = 23.9, label = "TB", size = 2, color = "dark blue")
# print completed plot…
> sp
w h i t e s p a c e
w h i t e s p a c e
NFL 2012 scatterplot – first take

NFL 2012 scatterplot – completed
w h i t e s p a c e
It’s common, almost necessary, to develop GGPLOT2 graphics iteratively. You can see that the first draft tends to crunch up the X-axis because of the handy automatic legend generated by the R package whenever a color gradient is used to embody a meaningful variable. An explicit command was used in the final pass to remove this default legend in favor of adding more information (above right). Here’s a ‘manual’ legend for the completed scatter plot, giving an idea of how many dimensions of meaning can be layered within a single, yet aesthetically pleasing graphic:
• Point Location, Vertical – avg points scored (PTS_OFF) (varies between 13 and 35)
• Point Location, Horizontal – avg points yielded (PTS_DEF) (varies between 15 and 30)
• Point Size – number of WINS on the season (varies from 2 to 13)
• Point Hue – POWER_RANK, a compilation of all other seasonal ranking categories (blue better; red worse)
• Green Diagonal Line – demarcates where points scored breaks even with points yielded
• Vertical Distance from Green Diagonal – overall offense/defense prowess (MARGIN)
• Shaded Region, Darker – Top quintile Offensive teams
• Shaded Region, Lighter – Top quintile Defensive teams
w h i t e s p a c e
A Little Data Analysis
In this plot, the better teams are located towards the ‘northeast’ quadrant while the worst teams reside in the ‘southwest’. Notice that just one team, DEN, the Denver Broncos, resides in both the top Offensive 20% and the top Defensive 20%. Compare plotted points for two of the teams, NYG and IND, or the New York Giants and the Indianapolis Colts respectively (easier if you expand the graphic). The first can be thought of as an example of an under-achieving seasonal result, while the second can be seen as over-achieving. While the Giants have quite a good average Offense/Defense advantage, more than +5, the same figure for the Colts is an unimpressive -2. The Giants also are within the top 20% league leaders in Offense, and they eclipse the Colts’ seasonal defense totals as well. Yet, the Giants had only 9 victories (and missed the playoffs) while the Colts produced 10. Looking back at the original data helps to explain all this by revealing that two critical late-season games were lost by the Giants while they were still in the playoff hunt. These losses came with uncharacteristically wide score margins: 0-34 and 14-33, and both were at the hands of other eventual playoff qualifying teams.
Projections Based On Outliers
Bill James is a well-known sports (baseball) statistician who rose from amateur obscurity to professional inner-circle consultant for the Boston Red Sox due to his Sabremetrics analytic methods. One of his interesting inventions, which has been adapted for the NFL by Football Outsiders, is the so-called Pythagorean Projection stat. The formula, also known as Pythagorean wins, has no derivational relationship to the famous Greek geometric rule concerning the square of the hypoteneuse; it borrows the name merely because it bears a certain superficial resemblance to the old rule. Roughly stated:
“The expected winning percentage of a team equals the square of the points scored divided by the sum of the squares of the points scored and the points allowed.”
Subsequent statistician work has refined the exponent for the Pythagorean Projection according to how many games a team plays within a given season. It turns out that baseball, with a 162-game regular season length, has an optimal predictive exponent of 1.83. Some have adopted an exponent of 2.37 for the NFL with it’s much shorter 16-game campaigns, in which “chance” can play a correspondingly greater role. Let’s implement a quick PL/SQL function embodying this formula, and then apply it to our NFL 2012 results dataset:
w h i t e s p a c e
CREATE OR REPLACE FUNCTION pythag_proj
(in_pts_for IN NUMBER,
in_pts_against IN NUMBER,
in_sport IN VARCHAR := "F")
RETURN NUMBER
IS
out_proj_winpct NUMBER;
l_exponent NUMBER;
BEGIN
IF UPPER(in_sport) = "B"
THEN l_exponent := 1.83;
ELSIF UPPER(in_sport) = "P"
THEN l_exponent := 2.00;
ELSE
l_exponent := 2.37;
END IF;
/** Compute expected winning percentage based upon victory margins… **/
out_proj_winpct :=
POWER(in_pts_for, l_exponent) /
( POWER(in_pts_for, l_exponent) + POWER(in_pts_against, l_exponent) );
RETURN out_proj_winpct;
END;
/
w h i t e s p a c e
When the projected wins according to this function differs from the actual by about ±2, the swing is considered very significant, and can even be used predictively to forecast a rise or drop in wins for the following season. According to FO, this rule of thumb has generally been upheld, though of course other factors apply and can mediate the results. If on the other hand, the difference is less than ±1, it is considered meaningless. As can be seen below, all but 11 NFL teams fall within the meaningless range for 2012, whereas 4 teams bear special watching: DET, HOU, IND, and ATL.
Of the four teams with ‘very’ significant differences between their actual and projected wins, only DET has underperformed based on their victory margins. The model suggests they are worth nearly 3 more victories than achieved. The other three teams, IND, ATL, and HOU are all projected to perform worse in the future. Note that the Pythagorean wins do not map evenly to forecasted win differentials for the following season; rather, a projected vs. actual differential of ±2 games is considered to map to about ±1 change in forecast wins.
w h i t e s p a c e
WITH pythag_wins AS
(SELECT team,
SUM(DECODE(wlt, 'WIN',1.0, 'LOSS',0, 'TIE',0.5, 0)) AS wins,
AVG(ptsf) AS pointsf, AVG(ptsa) AS pointsa
FROM nfl2012_scores GROUP BY team),
close_games AS
(SELECT team,
SUM(DECODE(wlt, ‘WIN’, 1, ‘TIE’, .5, 0)) AS closew,
SUM(DECODE(wlt, ‘LOSS’, 1, ‘TIE’, .5, 0)) AS closel
FROM nfl2012_scores WHERE ABS(ptsf-ptsa) <= 7
GROUP BY team)
SELECT team, wins, pointsf, pointsa,
16 * pythag_proj(pointsf, pointsa) AS proj_wins,
(16 * pythag_proj(pointsf, pointsa)) – wins AS proj_diff,
closew / (closew + closel) AS close_pct
FROM pythag_wins P, close_games C
WHERE P.team = C.team
AND ABS((16 * pythag_proj(pointsf, pointsa)) – wins) > 1.00
ORDER BY 6 DESC;
/
w h i t e s p a c e
The SQL query above is executed below, and results are sorted from highly underperforming to highly overperforming teams:
w h i t e s p a c e
TEAM WINS POINTSF POINTSA PROJ_WINS PROJ_DIFF CLOSE_PCT
==== ==== ======= ======= ========= ========= =========
DET 4 23.25 27.0625 6.58 2.58 .250
JAC 2 15.9375 27.75 3.39 1.39 .286
SEA 11 25.0625 15.0625 12.32 1.32 .556
CLE 5 18.875 23 6.16 1.16 .375
NO 7 28.8125 28.375 8.15 1.15 .571
NYG 9 26.8125 21.5 10.05 1.05 .429
TEN 6 20.625 29.4375 4.81 -1.19 .571
MIN 10 23.6875 21.75 8.81 -1.19 .833
HOU 12 26 20.6875 10.12 -1.88 1.000
ATL 13 26.1875 18.6875 11.04 -1.96 .778
IND 10 22.125 24.375 7.09 -2.91 .800
11 rows selected.
w h i t e s p a c e
Close Games vs. Blowouts
Another commonly accepted underperformance indicator (or an indicator that a team’s record stands to improve next year, all things being equal) is their low winning percentage in close games. Close games, for NFL purposes, are considered those whose winner and loser scores are within 7 points. If a team wins significantly better than 50% of it’s close games, it is likely living a charmed life. (There is much to dispute this too, but it supposedly holds true statistically over time.) In the SQL output above, the final (7th) column depicts close game performance. The report is sorted on the 6th column, so it is easy to compare the projected win disparity with the close game performance. They should correlate naturally, and ours do:
w h i t e s p a c e
# grab the data from the Oracle CSV file into R
> nfl <- read.csv("nfl2012_pythag.csv", header=TRUE, sep=",", as.is=TRUE)
> library(ggplot2)
# How well does projected difference correlate to close game performance?
> cor(nfl$PROJ_DIFF, nfl$CLOSE_PCT)
[1] -0.8668548
# execute basic scatter plot, x-y axes…
sp2<-ggplot(nfl, aes(PROJ_WINS, WINS, color=POINTSF-POINTSA))
sp2<-sp2+geom_point(shape=20, size=12*nfl$CLOSE_PCT)
+ scale_colour_gradient(low="black")
# generate title, labels, and breakeven slope line…
sp2<-sp2+xlab("Pythagorean Wins")+ylab("Actual Wins")
sp2<-sp2+ggtitle("NFL 2012 PYTHAGOREAN DISPARITY")
sp2<-sp2+geom_abline(intercept=0, slope=1, colour="red", size=.90)
# annotate each point with team name…
sp2<-sp2+annotate("text",y=2.1,x=3.7,label="JAC",size=2,color="brown")
sp2<-sp2+annotate("text",y=4.1,x=6.85,label="DET",size=2,color="brown")
sp2<-sp2+annotate("text",y=8.9,x=10.4,label="NYG",size=2,color="brown")
. . .
# display completed scatter plot…
> sp2
w h i t e s p a c e
In general, teams which have done poorly in close games have undershot their projected or Pythagorean wins. Perhaps only the Seattle Seahawks (SEA) stand out a little bit in this regard.
Let’s finish up with an R scatter plot for this latest data. Along the horizontal axis is projected wins, while actual wins are plotted vertically. The broad red diagonal slope is where these two quantities would coincide, and only those 11 teams whose projected versus actual wins differ by at least ±1 are depicted. (The remaining teams, if plotted, would all cluster near the red diagonal.) Teams south of the red diagonal are underperformers, while those north are overachievers. The other diagonals indicate bands of disparities between projected and actual of ±1 (orange) and ±2 (brown) respectively. The color of the point is used to indicate the average offensive/defensive margin (POINTSF minus POINTSA) over the course of the season, where more blue means positive and more black means negative values. Finally, the size of each point shows the relative winning percentage for close games only.
As mentioned above, we can expect a good statistical correlation between close game performance and Pythagorean wins disparity. This is demonstrated visually in the graphic. Teams above the diagonal have generally larger point sizes, and those below have generally smaller points. Blowout performance, by contrast, does not usually correlate well like this. (Incidentally, if you’d like to see a SQL query which contrasts blowout versus close game performance for all NFL 2012 teams, look at the bottom query within this listing.)
w h i t e s p a c e

teams with large disparity: projected vs. actual wins
Visually, it’s interesting to compare two pairs of similar teams: MIN (Minnesota Vikings) with IND (Indianapolis Colts), and HOU (Houston Texans) with NYG (New York Giants). Taking the first two, both teams have identical wins (10), and their point sizes are very close, showing similar competency within close games: (.833 vs. .800). Yet IND has a much lower projected win amount, and therefore overperformed as compared to MIN. Why? It turns out that IND did poorly in blowouts — games decided by at least 20 points. They were 0-3 in such games while MIN was 1-0. Now let’s compare the other two teams. Both share very similar projections as can be seen from their X-axis positions. Also, both are identically colored, medium blue, indicating healthy average scoring margins: +5.3125. So what is the explanation for HOU having three more wins than NYG? Here, the size of the points tell the story. HOU fared much better in close games than did NYG; they were 5-0 as opposed to 3-4. In summary, HOU significantly overperformed while NYG moderately underperformed, Pythagorean-wise.
~RS
