

E.F. ‘Ted’ Codd
SQL incorporates set operations in the various types of joins and anti-joins it allows, and also directly between tables or SELECT constructs via the operators: UNION, UNION ALL, MINUS, and INTERSECT plus IN and NOT IN. This post will explore this last group, saving joining as a future topic. Another closely related topic is the problem of finding and removing duplicated data within a set or table. This also deserves it’s own future post.
Scientific Research from DESPAIR.COM
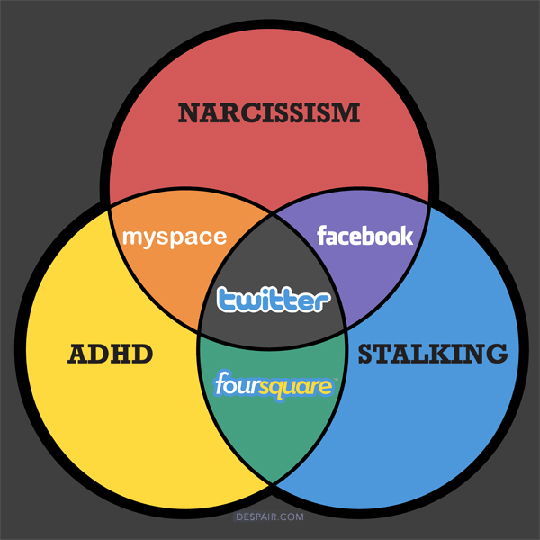
The basic “pretzel” shape illustrates the kinds of relationships possible between three interconnected sets. In the image at left, Facebook users are deemed to not be suffering from ADHD, although they are seen as prone to narcissism and stalking behaviors (purple). Foursquare people are happily more altruistic and less self-absorbed, but unfortunately they tend to exhibit attentiveness problems (green). The intersection of all three afflicted populations, those suffering from ADHD, Narcissism, and Stalking, is the sole province of Twitter users. (Not my opinions entirely, but can you really argue with science?) If we let A = the Narcissists, B = the Stalkers, and C = the ADHD people, then we can make the following subset formulations:
• A INTERSECT B = Twitter & Facebook users
• A INTERSECT C = Twitter & Myspace users
• B INTERSECT C = Twitter & Fourspace users
• A MINUS B = Myspace users & non-social-media Narcissists
• A MINUS C = Facebook users & non-social-media Narcissists
• B MINUS C = Facebook users & non-social media Stalkers
• B MINUS A = Foursquare users & non-social-media Stalkers
• C MINUS A = Foursquare users & non-social-media ADHD-ers
• C MINUS B = Myspace users & non-social media ADHD-ers
 You get the idea. When it comes to UNIONs, (AUB, AUC, BUC, and AUBUC), all four of the social media user groups will be represented within each union set along with various of the non-social-media user groups. For example, the only subset excluded from AUB are the non-social-media ADHD people (yellow).
You get the idea. When it comes to UNIONs, (AUB, AUC, BUC, and AUBUC), all four of the social media user groups will be represented within each union set along with various of the non-social-media user groups. For example, the only subset excluded from AUB are the non-social-media ADHD people (yellow).
Things get more complicated quickly as the number of sets increase, as evidenced by the image at right depicting the possible combinations of five different sets. There are 31 distinct subset combinations shown, or (2**5)-1.
FROM dual;
COMBOS
======
31
w h i t e s p a c e
If the empty set is included, meaning neither A nor B nor C nor D nor E, then we have 32 different possibilities.
UNION of Two Tables
The basic method to obtain rows from two similar tables is via the UNION verb. I say ‘basic’ because unlike with a join, you don’t concern yourself with downsizing the Cartesian product of the two tables by using join conditions such as foreign keys or other filters. At most you will have one output row for each table row. You just filter with the WHERE clause, if needed. I say ‘similar’ because you want the set of columns chosen from both tables in the union to match up. In the example below, you’ll see they needn’t be identical, as I’ve constructed a virtual column containing the literal ‘ –FREE SPACE– ‘ to match the segment info from the SYS.DBA_EXTENTS table. And I’ve done something similar for the absent EXTENT_ID column. What this query is doing is inspecting the system data dictionary to map out chunks of either free or utilized space, within a chosen tablespace. If utilized, the chunk is identified by it’s schema, segment name, and type; if unused it is simply labelled as free. The chunks are sorted by size across the union, in other words, independently of whether they are used or free.
w h i t e s p a c e
SELECT
owner||’.’||segment_name||’:’||segment_type S,
file_id F,
block_id BI,
extent_id EX,
bytes B
FROM sys.dba_extents
WHERE tablespace_name=upper(‘&&which_tablespace’)
UNION
SELECT
‘ –FREE SPACE– ‘ S,
file_id F,
block_id BI,
-1 EX,
bytes B
FROM sys.dba_free_space
WHERE tablespace_name=upper(‘&&which_tablespace’)
ORDER BY 5 DESC, 1, 4
/
UNDEF which_tablespace;
w h i t e s p a c e
The query results show that the original 100Mb tablespace (USERS) does not need coalescing and still has a relatively large chunk of contiguous free space (92Mb).
view query results
UNION vs. UNION ALL
When two sets are disjoint, meaning that they share no common elements, taking the union of them does not involve any second pass or extra work to eliminate duplications. That was the case with the query above gathering extents and free space chunks. When queries consider shared common rows within tables, duplicates can become an issue. This is the difference between UNION and UNION ALL: UNION will always eliminate duplicates, while UNION ALL allows them to be retrieved in the result set. This can have a performance impact if there are large tables involved and/or large numbers of tables. UNION ALL will be cheaper; it is necessary to weigh the business need for removing duplicates.
Let’s consider two tables of common given names, one from France and the other from the U.S. The tables have ranking information according to current popularity trends. Each contain the top 100 female and top 100 male given names for their countries of origin. I sourced this data on the web, and it was claimed to be accurate for 2011. I loaded them as external tables and then processed them into regular tables along with ranking information; the original frequency counts were removed for present purposes. We’ll explore the commonality between these two tables.
view French given names
view U.S. given names
COUNT(*)
========
200
rob@XE_11g2> SELECT COUNT(*) FROM top_usa_names;
COUNT(*)
========
200
rob@XE_11g2> SELECT COUNT(*) FROM
(SELECT given_name FROM top_french_names
UNION
SELECT given_name FROM top_usa_names
);
COUNT(*)
========
367
rob@XE_11g2> SELECT COUNT(*) FROM
(SELECT given_name FROM top_french_names
UNION ALL
SELECT given_name FROM top_usa_names
);
COUNT(*)
========
400
w h i t e s p a c e
As can be seen from the UNION count, there are 33 of the names which are duplicated somewhere among the French and U.S. English names. UNION ALL, however, counts everything. If you’re curious about the shared names between cultures, they will surface below. But first I want to give an inkling about the performance hit taken for UNION with non-disjoint tables. Because the data amounts (rowcounts) are so low, there is not a dramatic separation between the autotrace stats for the UNION vs. UNION ALL cases in our given names examples (button below right). But it is already clear that an extra step is added to the plan for UNION, and that higher costs are incurred in the Costs (CPU%) column. When serious quantities of data are involved, these add up. Moral of the story is to use UNION consciously when needed, and to rely upon UNION ALL by default.
INTERSECT
Now, back to tracking down those intercultural popular names! Our first take, illustrating the INTERSECT verb, might be this:
w h i t e s p a c e
2 INTERSECT
3 SELECT given_name FROM top_usa_names;
GIVEN_NAME
====================
ADAM
ALEXIS
ANDREA
ANNA
ANTHONY
CHLOE
CLAIRE
DAVID
DYLAN
EMMA
ETHAN
EVAN
JORDAN
JULIA
. . .
TOM
VICTORIA
WILLIAM
ZOE
30 rows selected.
w h i t e s p a c e
So, these thirty names occur in both the French and U.S. lists. This result doesn’t answer every question though, since we might wish to know why only 30 duplicated names have shown up common to both French and American English. Why aren’t there 33 names in the intersection? The following query reveals that the American English list itself contains three names which appear twice because they are popular for both genders.
w h i t e s p a c e
2 FROM top_usa_names
3 GROUP BY given_name
4 HAVING COUNT(*) > 1;
GIVEN_NAME COUNT(*)
============== ========
TAYLOR 2
JORDAN 2
SAM 2
rob@XE_11g2> SELECT given_name, COUNT(*)
2 FROM top_french_names
3 GROUP BY given_name
4 HAVING COUNT(*) > 1;
No rows selected.
w h i t e s p a c e
So, the French are not quite as lax about gender as the Americans when it comes to popular given names. Apart from this, you might recall that the name JORDAN also appeared above in the list of popular names common to both French and English. Putting together a final query, which collects all information from both tables relevant to duplicated popular names, including their country of origin, would look like this:
w h i t e s p a c e
WITH french_and_useng AS
(
SELECT given_name, ‘FRENCH’ AS lang, gender, ranking FROM top_french_names
UNION ALL
SELECT given_name, ‘US ENG’ AS lang, gender, ranking FROM top_usa_names
)
SELECT * FROM french_and_useng
WHERE given_name IN
(SELECT given_name
FROM french_and_useng
GROUP BY given_name
HAVING COUNT(*) > 1)
ORDER BY given_name, ranking ASC
/
w h i t e s p a c e
view query results
This result list produces both types of duplicates: the pairs of names shared across languages (black) as suggested by the original INTERSECT query above; and the pairs of names duplicated within the same language due to gender (red), including JORDAN, which is a hybrid of both conditions.
The WITH … AS construct allows us to obtain the supporting data for each name, like RANKING and GENDER. Look here for a more complex example of WITH … AS code. And, if you’re interested in contrasting recent baby naming trends in Britain and Wales against those in either the U.S. or France, check out this Guardian study.
MINUS
Finally, when we want to find only the rows within a given table which are not also found in some other table, a useful verb is MINUS. In our original pretzel graphic, the Myspace users (orange) plus the non-social-media ADHD-ers (yellow) represent the set ADHD MINUS the set of Stalkers. For our SQL example, imagine a replication scenario involving twin databases across a database link. We wish to check that all of the objects within a certain schema have been copied across to the same schema within the secondary database. The following snippet will in fact check for unmatched objects in both directions across the database link.
w h i t e s p a c e
PROMPT First Database?
ACCEPT db1
PROMPT Second Database?
ACCEPT db2
PROMPT Which Database Link?
ACCEPT dblink
/** Check in first direction… **/
ttitle center ‘OBJECTS WITHIN &db1 MISSING FROM &db2’ center skip 2;
SELECT object_name, object_type
FROM user_objects
MINUS
SELECT object_name, object_type
FROM user_objects@&&dblink
/
/** Check in second direction… **/
ttitle center ‘OBJECTS WITHIN &db2 MISSING FROM &db1’ center skip 2;
SELECT object_name, object_type
FROM user_objects@&&dblink
MINUS
SELECT object_name, object_type
FROM user_objects
/
tti off
undef db1
undef db2
undef dblink
w h i t e s p a c e
~RS

Good job Nice blog